Unlocking the Secrets Behind GenAI’s Mind-Blowing Answer Generation

Ever wondered what really goes on behind the scenes when generative AI platforms like ChatGPT or Claude dish out those snappy answers? It’s not just magic—or endless data dumps. Believe it or not, these platforms rely heavily on a multi-layered approach, and guess what? SEO still plays a starring role, but in very specific acts of this AI theater. While Google’s fresh AI optimization guidelines focus narrowly on its own search portal, the broader world of generative AI remains a bit of a mystery, especially when it comes to visibility and optimization tactics. So, how exactly do these AI systems pick, pull, and sometimes even invent the sources they cite? Buckle up because I’m about to unravel the four key steps—from training data to citation quirks—that shape every answer you see. Trust me, understanding this not only feeds your curiosity but could change how you approach your own content strategy in the age of AI. LEARN MORE.

Google’s recent AI optimization guidelines apply only to its search portal with AI Overviews and AI Mode, and not necessarily to Gemini or other generative AI platforms such as ChatGPT and Claude.
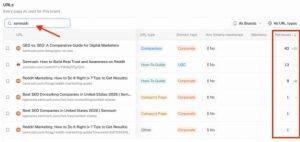
Visibility on those platforms is crucial, yet none provide guidance or suggest tactics. A useful first step is to understand how the platforms generate answers to prompts.
I’ll explain in this post.
1. Training layer
Upon receiving a prompt, genAI platforms first check whether their training data includes enough info on the topic to answer. In many cases, training data is sufficient, and the process stops there.
Training data doesn’t store URLs, nor does it rank sources, unlike traditional search engines. The data comes from known brands with clear value propositions that answer or solve a need.
2. Retrieval eligibility
Next, if the training data is insufficient, the platform will query search engines, as humans do.
At this point, visibility relies on search rankings. No genAI platform discloses where it searches, but studies reveal it is mostly Google. The platforms presumably rely on highly ranked URLs, although I’ve seen no definitive clarity on that selection process.
3. Extraction
At this point, a genAI platform has performed searches and found URLs for answers. Then it may crawl those pages to extract information.
This is where clear headings, short factual sentences, and Q&As lead to inclusion in answers, but only if the URL was found and crawled.
4. Citation-slot assignment
But inclusion does not always mean a citation. How do the platforms choose which sources to cite? In many cases, it’s not the source that supplied the answer.
Some independent studies suggest that citations originate in the retrieval stage (step 2 above) but were neither crawled nor used to create an answer. Others believe citations are part of official partnerships with publishers.
Some URLs are hallucinations and never existed.
Hence throughout the entire answer-generation process, SEO impacts only steps 2 and 3.
| Step | Purpose | Impact | Optimization |
|---|---|---|---|
| Training layer | Determine if answer already exists | Likely supplies the answer | Brand awareness, trust, clear positioning |
| Retrieval eligibility | Search Google for the answer | Possibly included in the answer if selected | SEO |
| Extraction | Assess potential answers on the page | Could provide an answer if crawled | SEO on page: Content clarity, structure, semantic relevance |
| Citation slots | Select pages to cite | URL can be cited but not included in the answer | Unknown |